How Machine Learning Predicts F1 Tire Degradation
How F1 teams use telemetry and ML (XGBoost, neural nets, Bayesian) to forecast tire wear, guide pit stops, and improve race strategy.

Formula 1 teams are using machine learning to predict tire wear and improve race strategies. By analyzing vast amounts of telemetry and race data, these models help teams decide when to pit, which tires to use, and how to optimize performance during a race. Here's what you need to know:
- Why it matters: Tire wear impacts lap times and pit stop strategies. Accurate predictions can mean the difference between winning and losing.
- How it works: Machine learning decodes complex patterns in data, like tire stress, track conditions, and driver behavior, to forecast degradation rates.
- Key data points: Models use telemetry, lap times, track temperatures, and fuel loads to make predictions.
- Real-world results: Teams like Mercedes-AMG PETRONAS and McLaren have achieved over 92% accuracy in predicting tire performance.
Machine learning isn't replacing human expertise but complements it by providing data-driven insights during races. This technology is reshaping how F1 teams approach tire management, saving costs and improving decision-making under pressure.
Machine Learning Pipeline for F1 Tire Degradation Prediction
How Do F1 Teams Predict Tire Degradation With Data? - The Racing Xpert
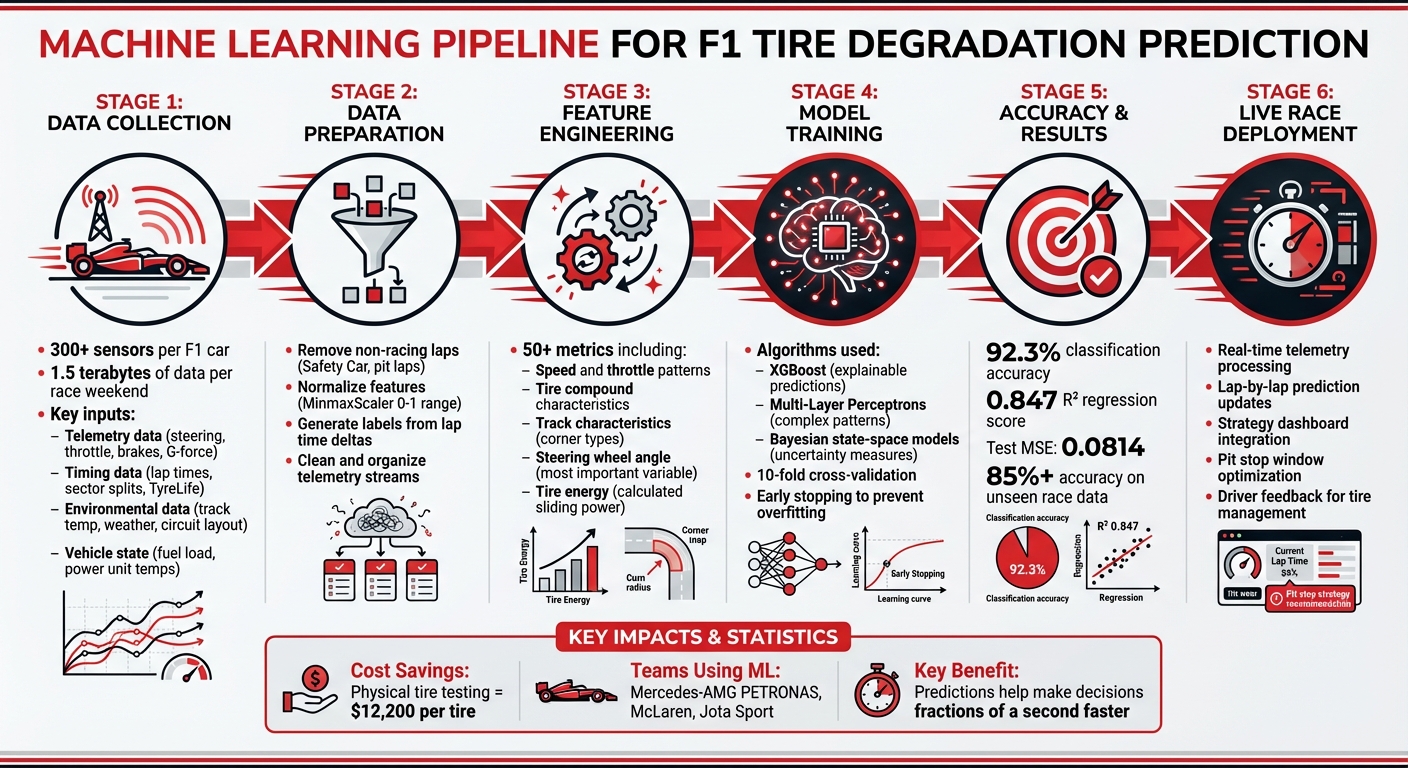
Data Collection: What Information Powers Predictive Models
The foundation of an accurate tire degradation model lies in gathering the right data. Modern Formula 1 cars are essentially high-speed laboratories, brimming with sensors that collect vast amounts of information. These datasets fuel machine learning models designed to predict tire wear.
"Formula 1 cars are effectively mobile laboratories, each one fitted with over 300 sensors that generate upwards of 1.5 terabytes of data across a race weekend." - Rohan Whitehead, Data Training Specialist, IoA Global
Data Sources and Parameters
Predictive models rely on several key data categories. Telemetry data is the cornerstone, capturing streams of information like steering inputs, throttle and brake usage, G-force patterns, and suspension movement. These measurements help quantify the physical demands placed on tires during every turn and straightaway.
Timing data provides performance insights, including lap times, sector splits, and "TyreLife" - the total laps completed on a given set of tires. For example, in June 2025, data scientist Raul Garcia analyzed 30 laps from Oscar Piastri's McLaren during the Spanish Grand Prix using the FastF1 library. By correlating TyreLife with lap times, his Multi-Layer Perceptron neural network modeled a smooth degradation curve.
Environmental and track conditions are crucial for context. Factors like track temperature, weather (including rain), and the layout of the circuit - such as the mix of slow, medium, and fast corners - significantly influence tire wear. Additionally, vehicle state data, such as fuel load and power unit temperatures, help account for the car's evolving weight during a race. For instance, even a 300-gram reduction in fuel can lead to measurable lap-time improvements, which must be distinguished from tire performance.
In January 2025, the Mercedes-AMG PETRONAS F1 team used historic race telemetry to train deep learning and XGBoost models. Their goal? To forecast "tyre energy" - a measure of the energy applied to each tire based on telemetry data. This method proved more precise than simply counting laps, as it captured the actual stress experienced by the tires.
Once collected, this diverse data must be processed and prepared for machine learning workflows.
Organizing Data for Machine Learning
Raw sensor data is just the beginning - preparing it for machine learning requires thorough cleaning and organization. Data cleaning involves removing laps that don't reflect true racing conditions, such as in-laps, out-laps, or those completed under Safety Car or Virtual Safety Car periods. Including these laps could skew the model's understanding of tire degradation.
Next comes feature normalization, which ensures consistent scaling of data. Tools like MinMaxScaler are often used to normalize inputs - such as lap times and tire life - into a 0-to-1 range, making them more suitable for neural network training. When processing Piastri's Spanish Grand Prix data, Garcia scaled both TyreLife and LapTime before feeding them into his model.
Finally, teams must tackle label generation. Since "tire condition" isn't directly measurable by sensors, teams create training labels by combining lap time deltas, Pirelli's expected tire life data, and actual pit stop timings. This process transforms raw telemetry into actionable inputs for machine learning, linking features like tire age and track temperature to outputs like predicted lap times or degradation rates.
Feature Engineering: Transforming Data into Model Inputs
Once data is collected and organized, the next step is feature engineering - turning raw inputs into meaningful variables that machine learning models can use. This process takes cleaned and structured data and converts it into features, the specific inputs that predictive models rely on to forecast tire wear. Essentially, it connects raw data to actionable model inputs, setting the stage for accurate predictions.
Main Features That Affect Tire Degradation
Several factors play a role in tire degradation. These include telemetry data, tire compound details, track-specific characteristics, and driver behavior. Let’s break these down:
- Telemetry Data: Metrics like speed and throttle provide a snapshot of the physical stresses tires endure during each lap.
- Tire Compound Information: Different tire compounds have unique degradation patterns. For example, soft compounds degrade faster, while harder compounds or intermediates may exhibit "negative degradation", where lap times stabilize or even improve as the track becomes more rubbered in.
- Track Characteristics: Tracks are often analyzed based on the proportion of slow, medium, and high-speed corners. Faster corners tend to put more stress on tires. Environmental factors, such as track temperature, humidity, and weather (like rain), also influence how tires wear over time.
- Driver Inputs: Driving style has a significant impact on tire wear. A study by Imperial College London and the Mercedes-AMG PETRONAS F1 Team in January 2025 highlighted steering wheel angle as the most critical variable for forecasting tire energy. Other important metrics include understeer/oversteer tendencies and the distance spent "lifting and coasting".
"SteeringWheelAngle, which affects how sharply the car takes corners, is the most important variable for forecasting tyre energies" - Jamie Todd, Imperial College London
Advanced Metrics for Better Predictions
Beyond the basics, advanced metrics allow teams to fine-tune their predictions by capturing subtle performance differences. Modern teams use over 50 metrics, including temperature gradients, pressure changes, and lateral acceleration - calculated by combining speed and steering data. These metrics help quantify the nuanced stresses tires face, particularly during cornering.
A standout metric in this context is "tire energy" - a calculated measure of sliding power based on forces acting on the tire and slip velocity. Unlike simple lap counts, tire energy reflects the real stresses tires experience during a race, leading to more precise predictions. For example, the Mercedes-AMG PETRONAS team used this metric in their 2025 study, analyzing telemetry data from 2020–2023 at 0.1-second intervals. By incorporating tire energy into their XGBoost model, they achieved a notable improvement in prediction accuracy.
In June 2025, Siddhant Gaikwad demonstrated the potential of advanced feature engineering in his comprehensive F1 analysis. By integrating over 50 indicators - including the effects of active aerodynamics and the performance of fully sustainable fuels - his model reached 92.3% accuracy in predicting tire degradation categories. Even when tested on unseen race data, the model maintained over 85% accuracy across different tracks and conditions. These advanced features not only enhance prediction accuracy but also ensure the models remain reliable across various scenarios, making them invaluable tools for racing teams.
Building and Training the Machine Learning Model
Once features have been carefully engineered, the next step is to teach models how to predict tire degradation using historical data. This involves selecting the right algorithm, training it with past race data, and validating its performance to ensure that the predictions are useful during live races.
Choosing the Right Machine Learning Algorithms
Each algorithm has its own strengths when it comes to forecasting tire wear. For example, Gradient-Boosted Trees (XGBoost) are a favorite when teams need clear explanations for predictions. XGBoost provides feature importance metrics and counterfactual explanations, which are crucial in high-stakes racing. In January 2025, researchers from Imperial College London and the Mercedes-AMG PETRONAS F1 Team used XGBoost to predict tire energy, combining it with explainable AI to refine pit stop strategies in real time.
On the other hand, Multi-Layer Perceptrons (MLPs) and other neural networks excel at identifying complex patterns in high-dimensional telemetry data. For instance, in June 2025, data scientist Raul Garcia developed an MLP using TensorFlow to model Oscar Piastri's soft tire wear. Using tire age (laps completed) as the main input, the model achieved a test Mean Squared Error (MSE) of 0.0814 after 55 training epochs. For even more intricate tasks, multi-task neural networks can tackle both regression (predicting lap time loss) and classification (categorizing degradation levels). Siddhant Gaikwad's F1 analysis platform used this approach, achieving a regression R² of 0.847 and a classification accuracy of 92.3% for tire degradation categories.
Bayesian state-space models offer another option, particularly when estimating hidden degradation dynamics from public timing data. These models provide probabilistic predictions and include uncertainty measures, making them ideal for strategy planning. In a 2025 study analyzing Lewis Hamilton's performance at the Austrian Grand Prix, researchers Cole Cappello and Andrew Hoegh showed that Bayesian state-space models outperformed traditional ARIMA(2,1,2) baselines.
"The state-space approach provides interpretable, probabilistic, and computationally efficient estimates of tire degradation."
– Cole Cappello
Training and Validation Process
Training begins with careful data preparation. Non-standard laps, such as those during safety car periods, pit stops, or under yellow flags, are filtered out. Lap times are converted into seconds for consistency. Normalizing input features ensures they are on a similar scale, which helps neural networks learn more effectively.
During training, historical data is fed into the model, and weights are adjusted to minimize prediction errors. Techniques like early stopping - halting training when validation performance stops improving, often after about 10 epochs - help prevent overfitting. Dropout layers, which temporarily deactivate random neurons during training, further enhance the model's ability to generalize.
Validation methods, such as 10-fold cross-validation or cross-season validation (e.g., training on 2022–2024 data and testing on 2025), ensure the model performs well under different track conditions and race formats. These steps are crucial for building models that can reliably predict outcomes during live races.
Measuring Model Accuracy and Practical Value
To evaluate how well a model performs, different metrics are used depending on the task. For regression tasks, such as predicting lap time loss, Mean Squared Error (MSE) measures the average squared difference between predictions and actual values. For instance, Garcia's MLP model for Piastri achieved a validation MSE of 0.0637. For classification tasks, like categorizing tire degradation into low, medium, or high levels, accuracy percentages indicate how often the model gets it right.
However, raw accuracy isn’t enough - models must also provide actionable insights. For example, during the first eight races of the 2025 season, predictive models identified an average time deficit of 0.085 seconds for Lewis Hamilton compared to Charles Leclerc after Hamilton's move to Ferrari. At the 2025 Canadian Grand Prix, Gaikwad's model suggested that a Medium-Hard one-stop strategy would be ideal for 78% of the drivers, with the Hard compound causing a +0.3 seconds per lap disadvantage compared to the Medium tire baseline.
Real-time validation during races adds another layer of reliability. Jota Sport used Monolith AI's self-learning models during the 24 Hours of Le Mans (2022–2025) to provide live feedback. By comparing predicted tire energy to actual stint averages, the team found that driver Anthony Davidson's second stint was only 0.4–0.5 seconds slower than his first. This insight helped them fine-tune their approach to key push-laps. Continuous evaluation like this ensures that models remain effective throughout race weekends.
Using Predictions During Live Races
Processing Live Data for Real-Time Predictions
During races, F1 cars continuously send telemetry data - like tire surface temperature, suspension travel, and G-force profiles - which is processed using edge computing techniques. This setup enables machine learning models to update predictions in real time, adapting to changing factors such as track conditions, fuel levels, and unexpected events like safety cars or weather shifts.
Machine learning models approach tire degradation as a hidden process, inferred indirectly through lap times and tire energy metrics. After every lap, the system recalibrates its predictions using incremental updates, filtering out laps influenced by safety cars, pit stops, or traffic. A notable example of this was during the 2025 Austrian Grand Prix, where a Bayesian state-space model updated degradation rates lap-by-lap. The model delivered real-time probabilistic estimates, outperforming traditional time-series methods. These updates seamlessly integrate into race strategy systems to refine decision-making on the fly.
Connecting Predictions to Strategy Tools
The real-time predictions feed directly into strategy dashboards, making the insights immediately actionable. These dashboards visualize key metrics like degradation curves and optimal pit stop windows. They also simulate scenarios such as undercut opportunities. For example, in January 2025, the Mercedes-AMG PETRONAS F1 Team leveraged deep learning and XGBoost models enriched with explainable AI techniques - such as feature importance and counterfactual explanations - to give strategists clearer insights into pit stop timing and tire compound choices.
Drivers also receive live feedback to help manage tire energy more effectively during their stints. A standout case occurred during the 8 Hours of Bahrain in November 2021, when Jota Sport utilized Monolith AI models to analyze driver performance in real time. The system highlighted differences in tire usage between drivers: Anthony Davidson kept a steady pace drop of just 0.5 seconds per lap, while Antonio Felix da Costa's higher tire energy usage led to a degradation of over 1.0 seconds per lap. This data allowed the team to provide immediate, actionable advice, helping drivers adjust their approach.
"The strategist still makes the call, but the machine learning model provides a level of situational awareness that no individual could maintain on their own."
– Rohan Whitehead, Data Training Specialist, IoA
Rather than replacing human decision-makers, these systems act as indispensable partners. They enhance situational awareness while engineers bring in the human element - like understanding a driver’s comfort level - that models might overlook. This collaboration ensures predictions remain effective, even under the intense, high-stakes conditions of Formula 1 racing.
Conclusion: Machine Learning's Growing Role in F1 Tire Strategy
Machine learning has reshaped how Formula 1 teams tackle tire degradation, offering a level of precision that traditional methods simply can't match. Models like XGBoost and Bayesian state-space frameworks excel at analyzing the complex interplay of factors like track temperature, driving style, and fuel load. Their ability to capture these non-linear relationships has led to impressive results, including a regression R² score of 0.847 and classification accuracy exceeding 92% for tire degradation predictions. When races are won or lost by mere fractions of a second, this kind of accuracy can make all the difference.
The financial impact is just as compelling. Physical tire testing costs around $12,200 per tire, which adds up quickly for teams operating under budget constraints. By shifting to data-driven virtual testing, teams can gather critical insights without the hefty price tag of traditional methods. These machine learning models deliver real-time feedback, cutting costs while boosting performance.
Transparency is another game-changer. Teams like Mercedes-AMG PETRONAS now use feature importance analysis and counterfactual explanations to dig into the "why" behind a model's recommendations - not just the "when". This level of clarity is crucial in high-pressure situations where split-second decisions can make or break a race.
While these methods are revolutionizing tire strategies, their influence extends beyond that. Machine learning is enhancing overall race operations, but tire performance remains a cornerstone of competitive success. As Rohan Whitehead from IoA aptly puts it:
"The fastest team isn't just the one with the best car. It's the one that understands its data the best, and uses it to make smarter decisions, sooner".
It's important to note that machine learning isn't replacing human expertise - it’s enhancing it. Engineers still rely on their instincts when it comes to driver comfort and race dynamics. Meanwhile, machine learning crunches hundreds of variables and simulates thousands of scenarios in an instant. This synergy between human intuition and machine precision is shaping the future of Formula 1, where every tiny advantage gained through data can translate into victory on the track.
FAQs
How does machine learning help F1 teams predict tire wear and improve strategies?
Machine learning has revolutionized how F1 teams handle tire strategy by enabling them to predict tire degradation with impressive precision. By crunching massive amounts of data - like lap times, fuel loads, tire temperatures, and cornering forces - advanced algorithms can uncover patterns that reveal how quickly tires lose grip in various conditions.
Armed with these insights, teams can make smarter, split-second decisions about pit stops and tire choices. For instance, strategists can calculate the trade-off between staying on a worn tire compound versus switching to a fresh one, factoring in how much time might be gained or lost. Real-time data updates during a race also let teams respond to sudden changes, such as rising track temperatures or the deployment of a safety car. This level of precision ensures teams can squeeze out every ounce of performance while managing risks - a critical edge that could turn a close race into a podium finish.
What data is used to predict F1 tire wear?
Predicting tire wear in Formula 1 hinges on analyzing high-resolution data gathered from the car during each lap. Key elements include telemetry data, which tracks wheel speed, throttle and brake inputs, g-forces, and tire-specific details like pressure, temperature (°C), and the energy absorbed by each tire. These inputs reveal how much strain the tires endure and how quickly they wear out.
In addition, lap-by-lap performance metrics - such as lap times, sector splits, stint lengths, tire compounds (hard, medium, soft), ambient and track temperatures, and fuel levels - play a crucial role. This information helps machine-learning models adapt to varying race conditions and tire dynamics.
Another essential component is historical race data, which includes archived telemetry and past tire performance records. This data trains the models to identify patterns in tire degradation. By integrating these diverse data sources, teams can leverage advanced algorithms to predict tire life with precision and refine their pit stop strategies.
How do F1 teams use machine learning alongside human expertise during races?
F1 teams leverage machine learning (ML) to enhance decision-making, working alongside human strategists rather than replacing them. ML models sift through vast amounts of data - such as tire performance, track conditions, and driver behavior - to predict tire wear and recommend the best pit-stop strategies. These recommendations are presented clearly, giving engineers a full view of the factors that shaped the analysis.
During the race, live metrics like lap times, sector splits, and tire temperatures are continuously compared with the model’s predictions. When unexpected events arise - like a safety car deployment or sudden weather shifts - strategists can step in and override the model’s suggestions. This blend of ML’s analytical power with human expertise ensures strategies remain grounded in data while staying flexible enough to adapt to the unpredictable nature of racing.